Mamba: Linear-Time Sequence Modeling with Selective State Spaces (Paper Explained)
Key Takeaways at a Glance
00:00Mamba is a linear-time sequence modeling architecture.00:45Mamba combines the advantages of Transformers and state space models.06:10State space models have fixed computations and no time dependence.12:30Mamba is a strong competitor to Transformers for long sequences.- Selective state spaces and discretization in Mamba
17:55Mamba architecture avoids the quadratic bottlenecks of attention-based models22:20SSM layer and forward propagation in Mamba31:15Utilizing GPU memory hierarchy in Mamba34:05Efficient computation via prefix sums / parallel scans in Mamba35:05Prefix sums are useful for efficient computation.37:27Mamba is a strong candidate for sequence modeling.37:44Efficient implementation is a key consideration.
1. Mamba is a linear-time sequence modeling architecture.
🥇95 00:00
Mamba is a new class of selective state space models that improves on prior work by achieving the modeling power of Transformers while scaling linearly in sequence length.
- Mamba allows the transition between time steps to be dependent on the current input, not the previous hidden state.
- The backbone of Mamba is a fixed computation, making it possible to precompute the whole sequence.
- Mamba is a hardware-aware algorithm that computes the model recurrently with a scan instead of a convolution, making it fast on GPUs.
2. Mamba combines the advantages of Transformers and state space models.
🥇92 00:45
Mamba retains the ability of state space models to compute all outputs in one swoop, while also allowing for context-based reasoning like Transformers.
- Mamba relaxes the input independence property of state space models, making it more similar to Transformers.
- Mamba can efficiently select data in an input-dependent manner, unlike prior state space models.
- Mamba achieves linear-time sequence modeling while still being able to perform context-based reasoning.
3. State space models have fixed computations and no time dependence.
🥈88 06:10
State space models, like S4, have fixed computations for transitioning between time steps and no time dependence or input dependence.
- The transition from one time step to the next is independent of the input.
- State space models have linear computations and no nonlinearity involved.
- State space models can efficiently compute all outputs in one big computation.
4. Mamba is a strong competitor to Transformers for long sequences.
🥈86 12:30
Mamba has shown promising results in terms of computational efficiency and scaling for long sequences, making it a strong competitor to Transformers.
- Mamba has not been tested on very large Transformers yet, but it has performed well up to 1 billion parameters.
- Mamba is particularly effective for tasks with long contexts, such as DNA modeling or audio waveforms.
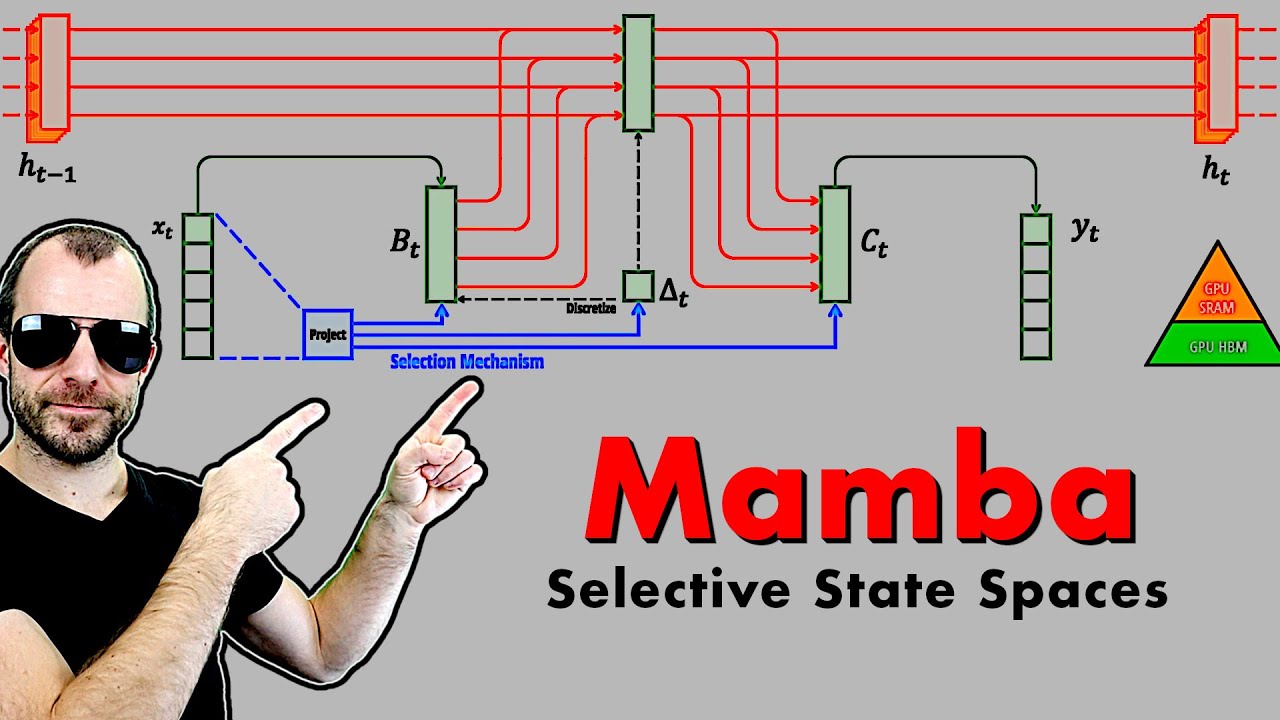
5. Selective state spaces and discretization in Mamba
🥈82
Selective state spaces in Mamba introduce input-dependent parameters and discretization. Discretization allows for the transformation of continuous time systems into discrete time systems. The input-dependent parameters and discretization result in a more complex but efficient architecture.
- Selective state spaces introduce input-dependent parameters and discretization.
- Discretization is a technicality that allows for the transformation of continuous time systems into discrete time systems.
- The input-dependent parameters and discretization make the architecture more complex but efficient.
6. Mamba architecture avoids the quadratic bottlenecks of attention-based models
🥈85 17:55
The Mamba architecture combines selective state spaces with other components like 1D convolutions and gating. It is attention-free, which allows it to avoid the quadratic bottlenecks of attention-based models like Transformers.
- Selective state spaces bring strong performance to dense modalities like language and genomics.
- Mamba recognizes that S4 is not suitable for language and adds selectivity to improve performance.
- The performance of Mamba may reach that of Transformers by making the transition dependent on the hidden state.
7. SSM layer and forward propagation in Mamba
🥇92 22:20
The SSM layer in Mamba considers the entire sequence as one during training. It uses linear projections, 1D convolutions, and a gating mechanism. Forward propagation is done by computing the next hidden state based on the previous hidden state and the input.
- Linear projections project each token individually, similar to MLPs in Transformers.
- The SSM layer has residual connections and operates from layer to layer.
- Forward propagation in Mamba is efficient and requires only constant time per step during inference.
8. Utilizing GPU memory hierarchy in Mamba
🥈88 31:15
Mamba differentiates between GPU high bandwidth memory (HPM) and SRAM. It performs computations in SRAM, which is faster, and reduces data movement between the two types of memory. This results in faster performance and reduced memory requirements.
- Moving big data between memory types is slow, so Mamba minimizes data movement.
- The fused selective scan layer in Mamba has the same memory requirements as an optimized Transformer implementation with flash attention.
- Mamba achieves fast performance by reducing data movement and recomputing intermediate states.
9. Efficient computation via prefix sums / parallel scans in Mamba
🥇91 34:05
Mamba uses prefix sums (parallel scans) to perform the zoom operation. This allows efficient computation by avoiding the need for constant kernel values. The prefix sum is computed using a reduction of data movement and recomputation of intermediate states.
- The zoom operation in Mamba is done differently from convolutions, using prefix sums.
- Prefix sums enable efficient computation by avoiding the need for constant kernel values.
- Mamba achieves efficient computation through reduction of data movement and recomputation of intermediate states.
10. Prefix sums are useful for efficient computation.
🥈85 35:05
Prefix sums can be used to efficiently compute cumulative sums or multiplications of different elements in an array.
- Prefix sums help avoid recomputing values and are used in various algorithms.
- They are particularly useful for scaling models with long sequence lengths.
11. Mamba is a strong candidate for sequence modeling.
🥇92 37:27
Mamba is a linear-time sequence model backbone that outperforms other attention-free models.
- It scales well with large sequence lengths.
- It has the potential to be a general sequence model backbone.
12. Efficient implementation is a key consideration.
🥉78 37:44
The efficient implementation of Mamba involves reducing memory transfer and optimizing code for different scenarios.
- The code base includes multiple implementations for Python, GPU, recurrent inference, and training.
- The step function in the code provides a good understanding of the architecture.

